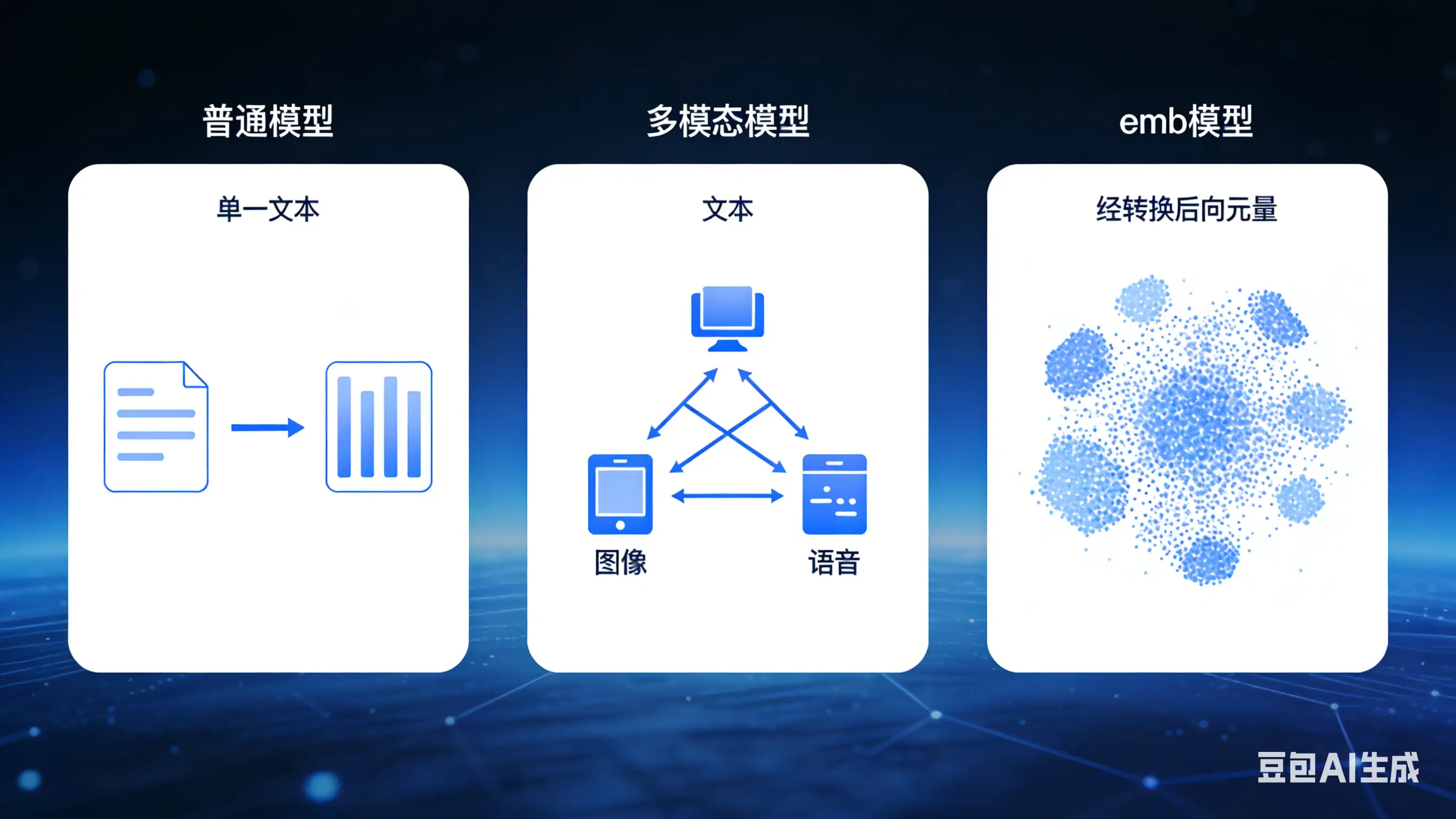
Core Differences Between General Models, Multimodal Models, and Embedding (Emb) Models
In the current rapid development of artificial intelligence, the term "model" frequently appears across many contexts, but model types differ greatly in positioning and functionality — general models, multimodal models, and Emb models (embedding models) may all fall under the AI model umbrella, yet their application directions and technical logic are completely different. Many people easily confuse these three, even using them interchangeably. This article will clearly break down their differences from four dimensions: definition, core function, technical characteristics, and application scenarios, helping you quickly clarify their positioning and value.
1. Clarify the core definitions first: the essential differences among the three
To distinguish them, first grasp their "core missions" — general models focus on "direct handling of single tasks," multimodal models focus on "fusing different types of information," and Emb models focus on "converting information into vectors." Their essential roles are completely different.
1. General models: "specialized processors" for single tasks
General models are the most basic and common AI models. Their core characteristic is "single input, single output," processing a single type of information and focusing on a specific task. They do not have cross-modal fusion capabilities and are not aimed at vectorizing information. The term "general" does not mean "mediocre performance" but indicates a relatively single scope and mode of processing — the basic form of AI models.
Put simply, a general model is like a "specialized worker" that only does one thing and accepts only one type of "raw material" (input data). For example, a sentiment analysis model that only processes text, a face recognition model that only processes images, and a numerical prediction model that only processes numeric data are all general models.
2. Multimodal models: "fusion processors" for cross-type information
The core feature of multimodal models is "multiple inputs, multiple outputs." They can handle two or more different types of information (i.e., "modalities") and achieve cross-modal understanding, conversion, and generation. "Modality" refers to the form in which information is presented, commonly text, images, speech, video, audio, etc.
A multimodal model is like an "all-around worker" that can process multiple kinds of "raw materials" simultaneously and fuse different types to complete more complex tasks. It breaks the limitation of general models in processing single information types and enables cross-modal scenarios like "text-image interoperability" and "audio-text conversion."
3. Emb models (embedding models): "vector converters" of information
The core mission of Emb models (short for Embedding models) is not to "directly perform tasks" but to "convert various types of information (text, images, speech, etc.) into vector forms that computers can understand." These vectors, called "embedding vectors," are low-dimensional, dense numerical representations that capture the core features of the information.
An Emb model is like a "translator": it does not directly complete specific tasks but translates human-understandable "natural information" (e.g., a sentence or an image) into a "numeric language" (vectors) that computers can understand. It does not have decision-making or generation capabilities by itself but serves as the foundation for many complex AI tasks, especially multimodal ones.
2. Core dimension comparison: understand the differences at a glance
| Comparison Dimension | General Model | Multimodal Model | Emb Model |
|---|---|---|---|
| Core mission | Process a single type of information to complete a specific specialized task | Fuse multiple modalities of information to complete cross-modal tasks | Convert various types of information into embedding vectors to provide feature representations |
| Input types | Single modality (text/image/speech, only one) | Two or more modalities (e.g., text + image, speech + text) | Can support single or multiple modalities (ultimately outputs vectors) |
| Output results | Concrete task results (e.g., class labels, predicted values, text replies) | Cross-modal results (e.g., image generation from text, speech-to-text + translation) | Low-dimensional embedding vectors (numeric sequences, not directly human-readable) |
| Technical core | Feature extraction and task adaptation for a single modality | Alignment, fusion, and cross-modal transformation of multimodal features | Feature compression and dimensionality reduction to retain core information and convert to vectors |
| Dependency relationship | Can work independently, not dependent on other models | Often relies on Emb models to provide vector representations of each modality to assist fusion | Does not complete tasks independently, often serves as a "preprocessing module" for other models |
3. Specific application scenarios: make the differences more intuitive
Theoretical comparisons are not intuitive enough. Combining specific application scenarios can make the differences clearer — in different scenarios, the roles of the three are very distinct and may even "collaborate."
1. Typical applications of general models
General models have the broadest range of applications, all being "single-task, single-modality," for example:
- Text: sentiment analysis (determining "This movie is great" as positive), text classification (sorting news into sports, entertainment, finance);
- Image: face recognition (identifying people in photos), image classification (distinguishing cats and dogs);
- Numeric: housing price prediction (predicting prices based on area, location), sales forecasting (predicting future sales from historical data).
The core of these scenarios is "input one type of information and output a clear task result." They do not require cross-modal fusion or vector conversion (even if internal conversion happens, it is not the core purpose).
2. Typical applications of multimodal models
Multimodal models center on "cross-modal collaboration," solving complex scenarios that general models cannot handle, for example:
- Text-to-image generation: input text like "a corgi running in the snow" and generate the corresponding image;
- Audio-text conversion: convert spoken input "The weather is nice today" into text; convert input text "There will be rain tomorrow" into speech;
- Visual question answering: input an image of a landscape + the question "What flowers are in the picture?" and output the answer "sunflowers";
- Video captioning: input a video (images + audio) and automatically generate corresponding text subtitles.
In these scenarios, the model needs to process two or more types of information simultaneously and understand their relationships to complete the task — something a general model cannot achieve.
3. Typical applications of Emb models
Emb models do not directly output "human-readable results," but they are the "foundational support" for many advanced AI tasks, such as:
- Semantic search: convert a user's query text (e.g., "recommend funny movies") into a vector and compare it with movie description vectors in a database to find the best match;
- Similarity judgment: convert two images or two sentences into vectors and compute vector similarity to determine if they are similar (e.g., decide whether two images are of the same object);
- Support for multimodal fusion: when a multimodal model processes "text + image," it often first uses Emb models to convert text and images into vectors, then performs fusion computations;
- Recommendation systems: convert user preferences and item information into vectors and use vector matching to recommend suitable items to users.
In short, Emb models are the "behind-the-scenes workers"; their value lies in simplifying complex information into vectors that computers can process, providing "raw materials" for other models (general or multimodal).
4. Key supplements: relationships and common confusions among the three
1. Relationship: not mutually exclusive, can collaborate
The three are not independent of each other and can work together to form more complex AI systems:
- Emb model + general model: for example, in a text retrieval system, an Emb model first converts text into vectors, and then a general classification model filters those vectors to obtain retrieval results;
- Emb model + multimodal model: almost all multimodal models rely on Emb models — for instance, a text-to-image generation model first converts text to vectors via a text Emb model and converts reference images to vectors via an image Emb model, then a multimodal fusion module processes them to generate a new image.
2. Common confusions explained
Many people confuse the three; the core issues are two common misconceptions, explained here:
-
Misconception 1: multimodal model = stacking multiple general models? Wrong. Stacking general models still means "each handles its own task" (e.g., a text model + an image model processing text and images separately, with no interaction); multimodal models are about "fusion" — understanding relationships between text and images, such as generating images from text, which cannot be achieved by simply stacking general models.
-
Misconception 2: Emb models are a type of multimodal model? Wrong. The core of Emb models is "vector conversion," while the core of multimodal models is "cross-modal fusion." Emb models can support multiple modalities (for example, converting both text and images into vectors), but they lack fusion, generation, and decision-making capabilities. Multimodal models may include Emb modules, but their roles are entirely different.
5. Summary: how to quickly distinguish and choose?
Remember three core criteria to quickly tell them apart and choose the appropriate model based on needs:
- If the requirement is to "process a single type of information and complete a concrete task" (e.g., text classification, face recognition), choose a general model;
- If the requirement is to "handle multiple types of information and achieve cross-modal conversion" (e.g., text-to-image generation, audio-text conversion), choose a multimodal model;
- If the requirement is to "convert information into vectors for retrieval/similarity/serving as support for other models," choose an Emb model.
Essentially, the three have "different divisions of labor": general models handle "specialized execution," multimodal models handle "cross-domain fusion," and Emb models handle "fundamental conversion." Together they form different layers of AI systems and support a wide range of AI applications from simple to complex.